Hoe menselijke vooroordelen in computerprogramma's sluipen
Taaltechnologie heeft in de afgelopen jaren zo’n ongekende ontwikkeling doorgemaakt dat de toepassingen ervan - denk aan autocorrect, Google Translate en Siri - niet meer zijn weg te denken uit ons dagelijks leven. Maar gebruikers staan nauwelijks stil bij de actieve rol die ze zelf spelen in deze technologie, en ze zijn zich te weinig bewust van de risico’s die gepaard gaan met de ontwikkelingen, zegt prof. dr. Malvina Nissim, hoogleraar Computationele Taalkunde en Maatschappij. Op 2 december houdt zij haar oratie.
Tekst: Marjolein te Winkel / Foto's: Henk Veenstra
We geven Siri de opdracht om ‘thuis’ te bellen om ons de moeite van een nummer intoetsen te besparen. We laten teksten door Google Translate vertalen en onze spelling door Word checken. En we hoeven in WhatsApp maar een paar letters te typen, of we kunnen al kiezen uit diverse mogelijke woorden. Aan de basis van deze en vele andere applicaties en diensten die we massaal hebben omarmd, staat computationele taalkunde: het vakgebied waarin taalkunde en kunstmatige intelligentie samenkomen.

Rare vertalingen
Het is geen wonder dat we allemaal graag gebruik maken van technologie, zegt Malvina Nissim. “Dat geldt ook voor mij. Als Italiaanse werkzaam bij een Nederlandse universiteit krijg ik geregeld teksten toegestuurd in het Nederlands. Het kost me veel tijd om ze in het Nederlands te lezen, dus roep ik soms de hulp in van Google Translate. Een paar jaar geleden kwamen daar vaak nog rare vertalingen uit, maar inmiddels zijn ze heel goed. Maar: niet perfect. Een computer kan fouten maken.”
Zo’n fout kan bijvoorbeeld ontstaan wanneer een uitdrukking letterlijk wordt vertaald - de woorden zijn correct vertaald, maar de betekenis is anders. Maar fouten kunnen ook voortkomen uit vooroordelen die een vertaalmachine zijn aangeleerd. Nissim: “Neem mijn moedertaal, het Italiaans. Die zit boordevol woorden met een mannelijke en een vrouwelijke versie. Je moet dus altijd kiezen. Ik ben professor en vrouw: una professoressa. Een mannelijke professor is un professore. Bij de vertaling ‘Ik ben professor’ gebruikt Google Translate standaard het mannelijke woord voor professor, tenzij ik er specifiek bij vermeld dat ik een vrouwelijke professor ben.”
Vooroordelen en stereotypes
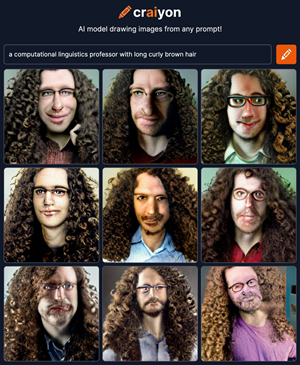
Niet alleen in een vertaalmachine kunnen vooroordelen sluipen. Als je googelt op afbeeldingen van een professor, zie je vooral plaatjes van witte mannen met een bril die voor een ouderwets krijtbord staan. Nissim: “Er is nu een programma, Crayon AI, dat op basis van een aantal woorden zelf een tekening kan maken, een nieuw beeld dat eerder niet bestond. Als ik mijzelf laat tekenen, en ik typ in: ‘een professor in computationele taalkunde met lang bruin krullend haar’, krijg ik negen opties: allemaal witte mannen met lang, bruin, krullend haar en een bril.”
Die bevooroordeelde houding ligt niet aan de technologie, haast Nissim zich te zeggen. “Om deze programma’s te ontwikkelen, laten we de computer een heleboel voorbeelden zien. Die voorbeelden, dat is wat jij en ik, wij allemaal, zelf maken: teksten, beelden, alles wat we op websites en in documenten achterlaten. Zo leren programma’s van de taal die wij gebruiken en nemen ze de vooroordelen en stereotypes die wij uiten over, zonder daar nuance aan te kunnen geven.” Hoge functies, zoals die van hoogleraar, worden nog altijd veel vaker bekleed door mannen dan door vrouwen. Er is dus meer data over mannelijke hoogleraren. “Maar er zijn wel degelijk vrouwelijke hoogleraren, en dat moeten we computers ook laten weten”, zegt Nissim.
Er zijn manieren om vooroordelen in computerprogramma's te verminderen, maar gemakkelijk is dat niet. “Daarvoor moet je al bij de ontwikkeling ingrijpen, en moet je bepalen wat een vooroordeel is en wat niet. Gender is een vrij opvallend voorbeeld, maar er zijn ook vooroordelen die veel subtieler zijn, en dus veel moeilijker om te bestrijden.” Bovendien is de data zelf niet representatief voor de samenleving als geheel. “Niet iedereen is online actief en niet iedereen wordt vertegenwoordigd in de data die wordt gebruikt om computermodellen te trainen. Sommige talen worden bijvoorbeeld weinig gebruikt, en sommige bevolkingsgroepen zijn ondervertegenwoordigd. Daarvan moeten we ons bewust zijn als we data gebruiken voor het bouwen van nieuwe applicaties”, zegt Nissim.

Bewustzijn
Om dat bewustzijn ook bij de toekomstige generatie te kweken, ontwikkelden Nissim en haar collega’s een reeks colleges voor derdejaars bachelorstudenten Informatiekunde over de ethische aspecten van computationele taalkunde. “Zij zijn de nieuwe generatie die in de toekomst de applicaties maken. Het is belangrijk dat zij naast alle technische kennis die zij opdoen ook nadenken over de mogelijke impact die de technologie heeft.”
En dat geldt wat Nissim betreft niet alleen voor de bouwers, maar ook voor de gebruikers. “Het is belangrijk dat zij weten dat deze computerprogramma’s niet objectief zijn, en dat niet alles wat ze online vinden de waarheid is”, zegt Nissim. “Er zijn inmiddels programma’s die op basis van een tekst heel realistische video’s kunnen maken. Het is verbluffend echt, maar niets in de video is echt gebeurd. Er worden steeds betere tools ontwikkeld die onjuiste informatie kunnen detecteren, maar tegelijkertijd wordt de technologie om die informatie te creëren ook steeds beter.”
Bang voor technologie moeten we vooral niet zijn, zegt Nissim. “Het is geweldig dat het allemaal kan, en natuurlijk maken we er graag gebruik van. Maar we moeten ons er bewust van zijn dat computerprogramma’s niet perfect zijn. We moeten kritisch blijven in hoe we de technologische mogelijkheden toepassen, en mens en machine moeten daarin samenwerken. Op die manier kunnen we de nieuwe ontwikkelingen blijven verwelkomen.”
Over Malvina Nissim
Malvina Nissim (1975) studeerde Taalkunde aan de Universiteit van Pisa en promoveerde in 2002 met onderzoek getiteld Bridging Definites and Possessives: Distribution of Determiners in Anaphoric Noun Phrases. Ze werkte aan universiteiten in Edinburgh, Rome en Bologna voor ze in 2014 begon aan de Faculteit der Letteren van de Rijksuniversiteit Groningen, waar ze in 2020 werd benoemd tot hoogleraar Computationele Taalkunde en Maatschappij. In 2017 werd ze uitgeroepen tot Docent van het Jaar van de Rijksuniversiteit Groningen.
Nissim leidt een onderzoeksgroep die onder meer werkt aan de verdere ontwikkeling van applicaties die interactie op basis van taal ondersteunen - zoals chatbots die het contact met klanten die een vraag of een klacht hebben kunnen afhandelen - en onderzoekt met behulp van computermodellen hoe taal en communicatie op basis van taal werken. Onlangs werd een publicatie die Nissim samen met promovendus Gosse Minnema, onderzoeker dr. Tommaso Caselli en twee collega’s van universiteit van Pavia schreef, uitgeroepen tot beste paper op een internationaal congres over taaltechnologie.
Meer informatie
- Malvina Nissim
- Malvina Nissim houdt op 2 december haar oratie
Meer nieuws
-
28 april 2026
Groningen op de kaart als Europese hiphophoofdstad
-
18 april 2026
Met kunst het klimaatonrecht te lijf
-