Projects
The members of the Computational Linguistics group are involved in a lot of projects. They are listed and briefly described here.
The Parallel Meaning Bank
The Parallel Meaning Bank is a NWO Vici project lead by Johan Bos. It is a semantically annotated corpus of English texts aligned with translations in Dutch, German and Italian. It aims to produce scoped meaning representations for all four languages in a language-neutral format, which in turn can be used to automatically find non-literal translations and estimate translation quality. There are multiple releases of this data already available. Also, as part of IWCS 2019, a shared task was organized on producing the scoped meaning representations for English!
The impact of aging, cognition, and sensory function on speech
This project explores the impact of aging on cognitive and sensory function, and how they interact with speech production. Speech motor control processes will be examined across age and in the two most prevalent neurodegenerative disorders that occur with older age: Alzheimer’s and Parkinson’s Disease. This project is funded by the NWO grant PhD in the Humanities is carried out by PhD student Katharina Polsterer under the supervision of Defne Abur and Martijn Wieling.
Vocal motor control of loudness
The neural mechanisms for vocal-motor control of loudness are influenced by the aging process in humans and other animals. The overarching goal of this interdisciplinary collaboration is to leverage strengths of animal and human models of vocalization to shed light on mechanisms underlying speech disruptions that occur in speech disorders. This project is funded by the Research School for Behavioral and Cognitive Neurosciences and is a collaboration between Defne Abur and Sanne Moorman (Faculty of Life Sciences and Engineering, RUG).
Dialects of Groningen: from text to speech:
In this collaborative project from Prof. dr. Martijn Wieling and Prof.dr. Jenny van Doorn, funded by the UG's Center for Information Technology, the goal is to develop several text-to-speech systems for Groningen dialects. These systems will be integrated in the online Groningen database Woordwaark. A regionally-sensitive TTS system will not only allow users of the website to hear these texts in their local variant, but they can also select other variants to become familiar with the variation of speech in the Groningen province. The second part of this project is to implement the text-to-speech systems that are the outcome of this project in robot service providers. The goal of this part is to discover whether the experience that in particular elderly citizens have with technology and their trust in technology may improve when regional language is used.
Neural Networks for Stylized Text Generation
Text generation, a subfield of natural language processing (NLP), leverages knowledge in computational linguistics and artificial intelligence to automatically generate natural language texts. In recent years, researchers begin to consider developing more anthropomorphic text generation technology as the development of artificial neural networks. Modelling and manipulating the style of the generated text (which can be named stylized text generation) is one of the most important directions of conditional text generation. For example, the formality of sentences (formal/informal), or the sentiment of product reviews (positive/negative). In his PhD project (2019-2023), Huiyuan Lai will explore approaches for developing neural models for text generation in different styles. Besides methodology of generation, evaluation for generated text is the other important part of this project.
Connecting the dots
This is a VENI project led by Arianna Bisazza. It started off as an effort to develop neural network based models of language and translation that are able to learn and exploit language structure effectively. The project's current main focus is to understand whether language structure, or grammar, is already implicitly captured by state-of-the-art neural models. This includes developing linguistically motivated benchmarks and probing tasks, or modifying existing neural architectures to make them more interpretable.
Dialects in flux
In this science communication project funded by the Royal Netherlands Academy of Science to the Speech Lab Groningen, the goal is to develop a board game in which players try to spread the dialect they represent across the Netherlands and Flanders. The game is developed by members of the Speech Lab Groningen with project lead Raoul Buurke.
MaCoCu
The MaCoCu project is an EU-funded project that focuses on creating high-quality corpora for under-resourced languages by collecting monolingual and parallel data from the internet. The project is a colloboration between the University of Alicante, the Jožef Stefan Institute, Prompsit and the University of Groningen. On our side, the project is carried out by Antonio Toral and Rik van Noord.
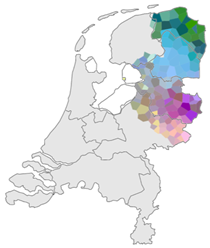
Automatic rating and recognition of Groningen speakers
This project uses data-driven approaches to study how pronunciation variation in the province of Groningen and the Low Saxon language area is distributed geographically, and how it has changed over time. In addition, we develop techniques that automatically rate how similar someone's pronunciation is to a specific regional target pronunciation. Finally, we aim to investigate how dialect affects cognition. This project is funded by both the Center for Groningen Language and Culture, the Faculty of Arts of the University of Groningen and the Centre for Digital Humanities of the University of Groningen. It is carried out by PhD-student Martijn Bartelds and supervised by Martijn Wieling.

Framing Situations in the Dutch (and Italian) Language
The Dutch FrameNet project is an NWO Free Competition Humanities project, in collaboration with the CLTC lab at VU University Amsterdam. The aim of the project is to study computationally how events and situations can be described in different ways using human language: from different perspectives and in different languages. For example, a description of a goal in a football match between Italy and The Netherlands would be very different depending on where it was written, or which language it was written in. FrameNet is an important resource for helping computers understand situations in human language. It was originally developed for English; in this project, we investigate how we can use machine learning techniques to apply existing systems for English to other languages, especially Dutch and to a lesser extent Italian. At CLCG, the people involved in this project are Gosse Minnema (PhD student), Malvina Nissim, Johan Bos, and Tommaso Caselli.
Speech planning and monitoring in Parkinson's disease: a speech motor control perspective
This project studies speech motor control of Parkinson's disease (PD) patients using articulographic methods, namely ultrasound tongue imaging and electromagnetic articulography. We are investigating which aspects of speech - planning or monitoring - are affected most in PD and assessing whether there are specific patterns in early- and late-stage PD that could help develop better diagnostic tools and speech therapies. This project is funded by the NWO grant PhD in the Humanities. It is carried out by PhD student Teja Rebernik under the supervision of Martijn Wieling, Roel Jonkers, Defne Abur and Aude Noiray (University of Potsdam).
"Van Old noar Jong"
In this Google-funded project of project lead Martijn Wieling, the Center for Groningen Language and Culture has developed and evaluates community-specific applications to teach the local Groningen variety to primary school children. This project originated through a collaboration with Dorpsbelangen Zandeweer, Eppenhuizen en Doodstil. The game has launched and can be freely downloaded for Apple and Android.
InDeep: Interpreting deep learning models for machine translation
The NWO-funded project InDeep (NWA-ORC) aims to empower users of deep learning systems for speech, text, and music applications by improving their ability to interact with neural network based models and interpret their behaviors. Within this project, the work package on Neural Machine Translation (NMT) led by Arianna Bisazza will develop new tools and methodologies to improve prediction attribution, error analysis and controllable generation for NMT systems. The research will be carried out by PhD student Gabriele Sarti under the supervision of Arianna Bisazza and Malvina Nissim.

Characterizing literary language
Literary language is different from ordinary language, but it is difficult to say exactly how. This project at the intersection of Computational Linguistics and Digital Humanities addresses this question. The data includes Dutch novels from The Riddle of Literary Quality. The project is conducted by Andreas van Cranenburgh.
Speech flexibility in adulthood following oral cancer treatment: Acoustic and kinematic explorations
Whenever we speak, we make use of both feedforward (stored motor programmes for specific sounds) and feedback mechanisms (where auditory and tactile feedback are used to correct our pronunciation). While there is lots of experimental evidence suggesting that people are very flexible in adapting to perturbations on the short-term (i.e. a bite block or lip tube), little is known about the long-term flexibility of our speech motor system. The central aim of this project ran by PhD-student Thomas Tienkamp is to investigate this long-term flexibility by following individuals who have been surgically treated for oral cancer. As treatment induces chronic anatomical changes, motor equivalence strategies have to be formed. We will capture these strategies using electromagnetic articulography and the acoustic speech signal. We also measure the individual’s reliance on both feedback mechanisms to investigate whether one mechanism better predicts the success of these strategies. This project is supervised by Martijn Wieling, Defne Abur and Max Witjes (UMCG).
Creativity and narrative engagement of literary texts translated by translators and neural machine translation
CREAMT is funded by the European Union’s Horizon 2020 research and innovation programme under the Marie Skłodowska-Curie grant and it is lead by Ana Guerberof and Antonio Toral. The project uses a novel, interdisciplinary approach to assess how effective machine translation (MT) is in literary translation by focusing on the creative aspect of literary texts and the ultimate user: the reader. The first phase analyses reproductions and creative shifts in three modalities: MT, human translation and MT post-editing, and two languages: Catalan and Dutch. Subsequently, the second phase measures the reader’s experience using narrative engagement and enjoyment scales borrowed from Psychology, Communication and Literary Studies.
Language policy and language change in the north of the Netherlands
Dialects in the Netherlands are known to become more similar to Standard Dutch over time. This project of Raoul Buurke (under supervision of Martijn Wieling) investigates the changing speech patterns of dialects in the north of the Netherlands on an aggregate level. By combining existing large phonetically transcribed datasets (extended with newly collected data using a mobile laboratory) with advanced statistical models, we are able to investigate these speech patterns across many decades. The data used for this project are constructed in such a way that we will be able to directly relate apparent-time and real-time approaches, which will shed light on the long-standing dilemmas between these methodologies. In line with recent studies, we also account for sociolinguistic variation in order to ensure accurate and reliable results of the dialectometric analyses. This includes a wide range of factors, such as individual change, speaker attitudes about particular language varieties, but also the ongoing changes in language policy in the Netherlands.
| Last modified: | 22 May 2025 12.55 p.m. |