Data Science: een frisse wind door fysica, genetica en geschiedenis
Weinig onderzoekers die met zoveel verschillende wetenschapsgebieden in aanraking komen als de data scientists van het CIT, het Centrum voor Informatie Technologie van de RUG. Het team voert een dertigtal projecten uit voor de meest uiteenlopende afdelingen van de universiteit.
Tekst: Jorn Lelong
In november 2016 ging het team Data Science op verzoek van de IT-strategiecommissie van de universiteit van start. Jonas Bulthuis van de CIT-afdeling Research and Innovation Support had al langer opgemerkt dat data science een serieuze opmars maakte en nam hierin het voortouw.
Verschillende achtergronden
Sindsdien is er een jaarlijkse call for proposals: onderzoekers van alle RUG-faculteiten kunnen een onderzoeksvoorstel inleveren voor data science-ondersteuning. Steeds meer faculteiten ontdekken de mogelijkheden van data science: de eerste ronde waren er veertien aanmeldingen, bij de tweede ronde was dat al gestegen naar zevenendertig. Inmiddels is het aantal data scientists gegroeid van twee naar tien mensen - met elk hun eigen expertise, zoals econometrie, fysica of wiskunde. “Als behoorlijk klein team is het noodzakelijk dat we elkaar goed aanvullen”, legt Jonas Bulthuis uit. “We willen mensen projecten geven waar ze energie uithalen.”
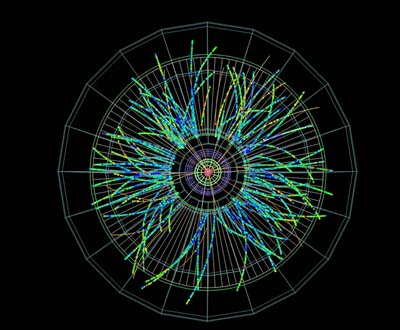
KVI: subatomaire deeltjes
Dat zie je bijvoorbeeld bij het dataproject voor het Kernfysisch Versneller Instituut (KVI). Dit project kwam vanwege hun affiniteit met het onderwerp in handen van Leslie Zwerver en Cristian Marocico. Cristian heeft zelf een achtergrond in fysica, wat volgens kernfysicus Johan Messchendorp erg goed van pas komt. Al enkele jaren legt Johan Messchendorp zich toe op deeltjesfysica, een onderzoeksveld binnen de fysica dat zich richt op subatomaire deeltjes, zoals protonen en neutronen. Die subatomaire deeltjes komen vaak alleen vrij door botsingen in deeltjesversnellers. Aangezien die deeltjesversnellers steeds meer botsingen per seconde aankunnen, wordt de hoeveelheid verzamelde data steeds groter. Klassieke onderzoeksmethoden stuiten hierdoor op hun limieten.
Glueballs
Daarom klopte Messchendorp aan bij het team Data Science. Met machine learning, een onderzoeksmethode binnen artificiële intelligentie om grote hoeveelheden data te analyseren en daarin patronen bloot te leggen, kunnen data scientists Leslie en Cristian interessante deeltjes filteren van de enorme hoeveelheid achtergrondinformatie. Dat moet allemaal online, want geen computer kan de data aan die hun algoritme erdoor jaagt. Concreet willen ze machine learning gebruiken om gluonen te reconstrueren. Gluonen zijn kerndeeltjes die erg veel informatie bevatten, maar heel moeilijk te zien zijn. Ze komen namelijk alleen in combinatie met andere deeltjes voor. Daarom wil Messchendorp protonen met antiprotonen laten botsen om glueballs te creëren, exotische toestanden die gluonen bevatten. Toch blijft het zoeken naar een speld in een hooiberg: zo’n exotische toestand komt slechts een in de 100 miljoen botsingen voor.
Nieuwe wind
In afwachting van een gloednieuwe, hypersnelle deeltjesversneller in Darmstadt, baseren Cristian en Leslie zich op experimenten bij een deeltjesversneller in China met lagere snelheden. “Die data is nog behapbaar. Daar kunnen we mee spelen om de techniek te optimaliseren en deep learning te vergelijken met de traditionele methoden”, zegt Messchendorp. De eerste tekenen zijn positief. In enkele maanden hebben Leslie en Cristian een algoritme ontwikkeld dat zich staande houdt tegenover de klassieke methoden. Volgens Messchendorp zijn zulke vergelijkende tests noodzakelijk om een nieuwe wind door de fysica te laten waaien. “Als je met een nieuwe methode komt, moet je overtuigend kunnen aantonen dat het werkt.”
Ook data scientist Dimitrios Soudis merkt dat de academische wereld zich doorgaans traag openstelt voor nieuwe technieken. “Academici willen voornamelijk in wetenschappelijke tijdschriften publiceren. Als die nog geen interesse hebben in bepaalde nieuwe technieken, dan wacht de academicus ook met zich daarin te verdiepen. Daarom duurt het altijd enige tijd voordat innovaties van het ene gebied overslaan op het andere.”
(Tekst gaat verder onder de afbeelding.)

GCC: een nieuwe screeningtool voor erfelijke ziektes
Het Genomics Coordination Centre, de afdeling Bio-informatica van het UMCG, vormt daar in zekere zin een uitzondering op. Al meer dan tien jaar doet de afdeling uitgebreid dataonderzoek. Zo was het UMCG in 2014 betrokken bij Genome of the Netherlands, een gigantisch nationaal dataproject. Toch is er een groot verschil tussen data verzamelen en meer geavanceerde technieken zoals machine learning. “Door onze jarenlange dataverzameling kunnen we goed goedaardige van kwaadaardige genvariaties in het DNA van mensen onderscheiden. Maar wat we nog niet konden, is voorspellen of een onbekende genvariant tot ziektes kan leiden”, zegt Joeri van der Velde, genspecialist van het UMCG.
Machine learning-model
Daarom klopte hij aan bij het CIT. Het doel was om CADD, de meest gebruikte annotatiemethode om genetische mutaties op te delen, aan te passen aan hun onderzoeksvraag. “Maar in plaats van die bestaande methode aan te passen, gebruikten we de achterliggende informatie en goten we het in een nieuw machine learning-model. Eigenlijk startten we dus opnieuw”, aldus Soudis. Al binnen twee weken volgden veelbelovende resultaten. “Het was spannend, maar toen we ons algoritme op de nieuwe data toepasten, bleek het ook te werken,” zegt Dimitrios. “Ik dacht echt: hoe kan het dat niemand dit eerder geprobeerd heeft?”
Toegevoegde waarde
Ook Joeri van der Velde was verbaasd door de snelle resultaten. “Voor veel van onze onderzoeksvragen werkt het nu al beter dan bestaande methodes. Dat is veel sneller dan verwacht.” De toegevoegde waarde van machine learning-experts zit volgens hem vooral in de toepassing van het algoritme. “Ik dacht altijd dat het bouwen van het algoritme het moeilijkste was. Maar daarna moet je precies weten hoe je dat algoritme toepast op je onderzoeksvraag. Dat is eigenlijk een hele kunst op zich.”
Erfelijke ziektes voorspellen
Het algoritme is nu al in staat om op efficiënte wijze pathogenische (ziekteverwekkende) genvarianten te onderscheiden van de duizenden onschadelijke. Bovendien kun je op basis van dit model die genetische variaties aan specifieke eigenschappen linken en voorspellen of nog onbekende genvarianten binnen het DNA mogelijk ziekteverwekkend zijn. “Dankzij dit project kunnen we erfelijke ziektes op termijn veel sneller vaststellen en voorspellen. Dat is best een grote stap.”

Een virtuele reis naar het zeventiende-eeuwse Nederland
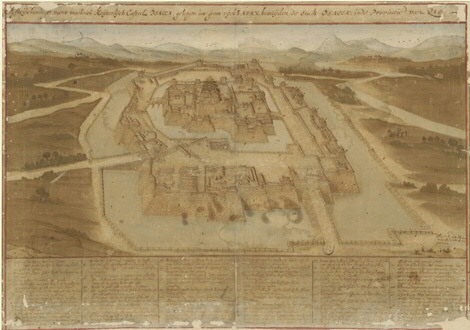
Ook bij de faculteit der Letteren van de RUG groeit het besef dat data science een interessante aanvulling kan zijn op de klassieke onderzoeksmethodes. Sabrina Corbellini, professor ‘History of Reading in Premodern Europe’, doet historisch onderzoek naar de reizen van Cosimo III de’ Medici. Als deel van de roemrijke Florentijnse bankiersfamilie werd hij groothertog van Toscane aan het eind van de 17de eeuw. Hij had een fascinatie voor Nederland en tussen 1667 en 1669 maakte hij twee reizen naar de Republiek.
Oud-Italiaans
De verschillende kaarten en dagboeken, die eeuwenlang bewaard werden in de Biblioteca Medicea Laurenziana in Florence, bieden een schat aan informatie over die reizen. “Cosimo ging langs bij kunsthandelaars, schrijvers en krantenverzamelaars. Hij bezocht verschillende steden en sprak met stadhouders. En dat is allemaal quasi per uur genoteerd in zijn dagboeken.” Aan de hand van die dagboeken wil Corbellini achterhalen met wie Cosimo in contact kwam, en – als het even kan – om welke reden. Maar Oud-Italiaanse dagboeken doorlezen en analyseren is een tijdrovende taak. Daarom vroeg ze aan data scientists Venustiano Soancatl Aguilar en Nicoletta Giudice een script te maken om snel locaties, personen en plaatsnamen te labelen in de dagboeken.
Tijdwinst
Voor Venustiano Soancatl Aguilar is het de eerste keer dat hij aan historisch onderzoek deelneemt. “Eerder deed ik projecten met real-time data over lichaamsbeweging, of dataonderzoek over sterrenkunde. Daar werk je met veel grotere datasets. Toch betekent dat niet dat dit project makkelijker is. Cijfers zijn universeel, betekenen altijd hetzelfde. Maar werken met taal is gecompliceerder, een woord kan verschillende betekenissen hebben.” De dagboeken zijn bovendien in Oud-Italiaans geschreven, wat het er niet makkelijker op maakt. Gelukkig kan zijn Italiaanse collega Nicoletta Giudice daar een handje bij helpen. “Machine learning alleen zal je niet vertellen of je fouten maakt. Daarom controleert Nicoletta en geeft ze feedback, zodat we het model kunnen optimaliseren.” Het optimaliseren is de moeilijkste taak, maar op lange termijn levert het tijdwinst op. “Als het model eenmaal werkt, kun je het binnen een paar seconden op andere documenten toepassen. Dat gaat veel sneller dan manueel 100 boeken analyseren.” Voor Sabrina Corbellini is de samenwerking met data scientists een primeur. In de toekomst ziet ze mogelijkheden om het vaker te doen.
Meer informatie
Kijk op onze Data Science website.