Data Science: a breath of fresh air for physics, genetics and history
Few university researchers get as much interaction with other fields of science as do the data scientists at the CIT, the Center for Information Technology at the University of Groningen. The team is currently involved in around 30 projects within a wide array of University departments.
Text: Jorn Lelong
The Data Science team was created in November 2016, on the request of the University’s IT Strategy Committee. Jonas Bulthuis from the department of Research and Innovation Support at the CIT was already aware that data science had been seriously advancing for some time, and so he decided to take the lead.
Different backgrounds
Since then, there has been an annual call for proposals: researchers from all UG faculties can submit their research proposals for data science support. More and more faculties are discovering the possibilities of data science. In the first call for proposals, there were around 14 submissions – but by the second round, this had already increased to 37. In the meantime, the number of data scientists has grown from two to 10 and each has their own expertise, such as econometrics, physics or maths. “Since we’re a relatively small team, it’s crucial that we complement each other”, says Bulthuis. “We want to give people projects that give them energy.”
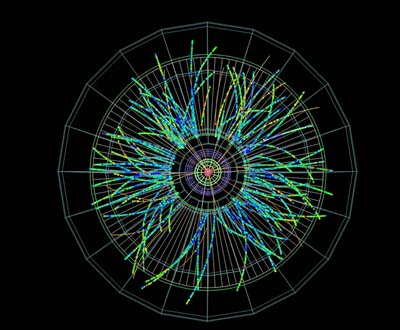
KVI: subatomic particles
This can be seen in practice, for example in the data project for the Center for Advanced Radiation Technology (KVI-CART). The project fell in the hands of Leslie Zwerver and Cristian Marocico due to their affinity with the subject. Marocico has a background in physics himself, which, according to nuclear physicist Johan Messchendorp, has proven to be very useful. For a few years now, Messchendorp has been focusing on particle physics, a field within physics that concentrates on subatomic particles like protons and neutrons. These subatomic particles are only visible when they collide at a high speed in particle accelerators. Seeing as particle accelerators enable an increasing number of collisions per second, the amount of data expands equally. Because of this, conventional research methods no longer do the trick.
Glueballs
This is why Messchendorp called on the Data Science team. With machine learning, which is an AI research method used to analyse a large amount of data and reveal patterns within it, data scientists Zwerver and Marocico have been able to filter interesting particles from the enormous amount of background information. All of this data has to be processed online, as no single computer could handle the amount of data that their algorithm goes through. Specifically, the data scientists want to use machine learning to reconstruct gluons. Gluons are nuclear particles that carry a vast amount of information but that are also very difficult to see. And they only appear in combination with other particles. For this reason, Messchendorp wants to make protons and anti-protons collide in order to form glueballs, exotic structures that contain gluons. But this is like looking for a needle in a haystack, as such exotic structures only appear once per 100 million collisions.
A breath of fresh air
In anticipation of the brand-new high-speed particle accelerator currently being built in Darmstadt, Germany, Marocico and Zwerver are basing their experiments on a particle accelerator in China that runs at a slower speed. “These data are still manageable. We can use them to optimize our technique and to compare deep learning with more conventional methods”, Messchendorp explains.
The first signs seem promising. Over just a few months, Zwerver and Marocico have developed an algorithm that stands up to traditional methods. According to Messchendorp, these kinds of comparative tests are essential to giving physics a breath of fresh air. “If you create a new method, you need to be able to convincingly demonstrate that it works.”
Data scientist Dimitrios Soudis also recognizes that the academic world can be slow to welcome new techniques. “Academics mainly want to publish in journals. If the journals are not yet open to new techniques, the researcher will also hold back. This is why it takes a while for innovations to reach other fields of research.”
Text continues below the image

GCC: a new screening tool for hereditary diseases
The Genomics Coordination Centre within the department of Bioinformatics at the UMCG is an exception in this regard. The department has been conducting extensive data research for more than a decade already. In 2014, the UMCG was involved in the extensive national data project ‘Genome of the Netherlands’. Even so, there is a big difference between data gathering and more advanced techniques like machine learning. “Through our data gathering over the years, we had become good at differentiating between benign and malignant genetic variations in people’s DNA. But what we were still not able to do was to predict whether an unknown genetic variation could lead to disease”, says Joeri van der Velde, genetic specialist at the UMCG.
Machine learning model
For this reason, van der Velde called on CIT. The aim was to adjust the CADD model, which is the most-used annotation method for splitting up genetic mutations, to their research question. “Instead of applying the existing CADD method, we took the background information behind it and put this into a machine learning model. So, we actually started from scratch”, says Soudis. After just two weeks, promising results appeared. “It was exciting, and then when we applied our algorithm to new data it also seemed to work”, says Soudis. “I honestly thought: how is it possible that nobody has tried this before?”
Added value
Van der Velde was equally surprised by the quick results. “In terms of answering many of our research questions, our method already outperforms existing methods. This is happening much quicker than we expected.” According to van der Velde, the added value of machine learning experts mostly lies in their application of the algorithm. “I always thought that building the algorithm was the most difficult part. But after that, you need to know exactly how to apply the algorithm to your research question. And that is actually a whole art in itself.”
Predicting hereditary diseases
The algorithm is already able to efficiently identify pathogenic genetic variations from the thousands of harmless ones. Moreover, the model allows researchers to link genetic variations to specific characteristics and to predict whether as-yet-unknown genetic variations within DNA could be pathogenic. “Thanks to this project, we can now determine and predict hereditary diseases much quicker. This is definitely a big step.”

A virtual journey to seventeenth-century Netherlands
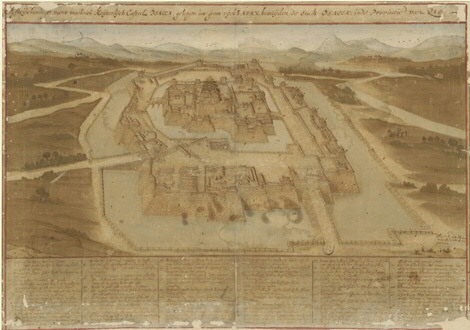
At the UG Faculty of Arts, there is also growing awareness that data science could complement traditional research methods in an interesting way. Sabrina Corbellini, Professor of History of Reading in Medieval Europe, is conducting historical research into the journeys of Cosimo III de’ Medici. As the member of an illustrious Florentine banking family, he became the Grand Duke of Florence at the end of the seventeenth century. He possessed a fascination for the Netherlands and travelled to the Dutch Republic twice between 1667 and 1669.
Old Italian
The various maps and diaries that were kept for centuries in the Laurentian Medici Library in Florence contain a wealth of information about Cosimo’s travels. “Cosimo visited art dealers, writers and newspaper collectors. He went to different cities and spoke to mayors. And all of this is noted in his diaries, almost exactly to the hour.” By studying these diaries, Corbellini wants to discover who Cosimo met with and – if this is even possible – for what reason. But reading and analysing diaries written in Old Italian is a time-consuming task. Corbellini therefore asked data scientists Venustiano Soancatl Aguilar and Nicoletta Giudice to make a script allowing them to quickly label the locations, persons and place names in the diaries.
Saving time
For Soancatl Aguilar, this is the first time that he has participated in historical research. “Previously, I worked on projects about bodily movement using real-time data, or projects on astronomy. In those projects, I worked with much larger data sets. But that doesn’t mean that this project is easier. Numbers are universal, they always mean the same thing. But working with language is much more complex – a word can have multiple different meanings.” Besides that, the diaries are written in Old Italian, which doesn’t make things any easier. Luckily, his Italian colleague Nicoletta Giudice is able to help out. “Machine learning alone won’t tell you if you’ve made mistakes. Therefore, Nicoletta monitors the process and gives feedback, so that we can optimize the model.” Optimizing the model is the hardest task, but it saves time in the long run. “Once the model works just once, you can easily apply it to new documents in a few seconds. This is a lot faster than analysing 100 books manually.” For Corbellini, this is the first time that she has worked together with data scientists – but she can already see possibilities for doing it more often in the future.
More information
Visit our Data Science website.
More news
-
-
15 September 2025
Successful visit to the UG by Rector of Institut Teknologi Bandung
-