
Frequently Asked Questions

We receive daily questions from individual researchers and/or support staff working with or interested in research analytics. This FAQ aims to capture some of the most frequent or intriguing questions we have received and our attempt to provide an answer and guidance. If you cannot find the answer to your burning question below, don't hesitate to contact us at rise rug.nl.
Planning Academic & Societal Impact
How can I plan my impact with the SMART method?
SMART stands for Specific, Measurable, Achievable, Realistic, Timely.
When planning the impact for your research, make sure your project and objectives meet those five goals.
|
What is SMART planning?
|
Example
|
||
|
S
|
Specific
|
Be as specific as possible when defining your impact goals. Ask yourself questions following the 5 W's: Who, What, When, Where and Why?
|
You are presenting your latest research at a scientific conference in Amsterdam, in a month. Your goal is to attract new collaborations with international peers in your field.
|
|
M
|
Measurable
|
Can you track your progress and measure your impact success? How? For tips, check out our page About measuring impact.
|
Before: you advertise your upcoming talk on social media and on your blog. Track altmetrics to assess your reach.
During: How many peers in your field attend the conference? How many attend your talk?
After: How many peers get in touch with you? Does your talk get shared on social media?
|
|
A
|
Achievable
|
The key to success is to set a goal that is just the right level of challenge to drive your progress: neither too easy nor too difficult to complete. Look at your current situation: do you have what you need to achieve your impact goal?
|
Do you have evidence that this method has helped you find collaborations in the past? Name all the resources that can help you reach your goal (social media, word-of-mouth, newsletters...) and use them.
|
|
R
|
Realistic
|
Is this impact goal worthwhile to you? Are you the right person to achieve it or should you delegate? Is it applicable to your current situation or unrealistic (see A - achievable)?
|
You realize you are not comfortable with using altmetrics to measure your success. You
contact the RISe team
to get appropriate support.
|
|
T
|
Timely
|
Assign a start and end date, possibly adding stepping stones in between, to ensure you are on track with your impact goal
|
You create a table with the important dates and corresponding goals to be achieved by then: before, during and after your talk.
|
How do I budget my research's impact?
Budgeting your research's impact is a crucial part of planning to ensure your research reaches and influences the intended audience effectively. Budgets vary depending on your activities, needs and fundings. Here, we provide general guidelines to help you get started.
Before anything else, make sure to define your research impact goals by identifying your target audience and outlining your impact objectives.
1. Plan your impact activities
-
Dissemination: Plan how you will share your research findings (e.g., academic publications, conferences, workshops, webinars, social media).
-
Engagement: Engage with stakeholders through focus groups, advisory boards, or collaborative projects.
-
Communication: Develop communication materials such as policy briefs, infographics, videos, and press releases.
2. Allocate resources accordingly
-
Personnel Costs: Budget for salaries, stipends, or consultancy fees for those involved in dissemination and engagement activities.
-
Event Costs: Include costs for organizing and attending conferences, workshops, and other engagement events (e.g., venue hire, travel, accommodation, catering).
-
Communication Costs: Consider expenses for designing and producing communication materials, maintaining a website, and utilizing social media platforms.
-
Monitoring Costs: Will you need to set aside a budget to track your impact? The UG's Research Intelligence Services are free to all university members, but if you decide to use metrics and tools other than those provided by us, you will need to take this into account in your research impact budget.
For more in-depth advice on budgeting and funding, contact the funding team.
Do I get funds to finance my impact efforts?
Find out all about Funding on the UG's Research Portal. If you have more questions, contact the university Funding Team.
Where do I find collaborators?
Research collaborations can significantly enhance the quality, scope, and impact of scientific investigations. But where do you find potential collaborators?
There was a time when word-of-mouth, relations and conference networking were pretty much the only ways to strike new research collaborations. Nowadays, it is easier to find a perfect match through online tools and database.
You can start with networks such as ResearchGate to find researchers in your topic of interest. You can also utilize the powerful tools of SciVal and Altmetric in similar ways (ask for RISe support at rise rug.nl). There are also specific platforms dedicated to finding collaborations:
Find collaborators in Europe
-
Enterprise Europe Network (EEN) is the world's largest innovation support network
-
Community Research and Development Information Service (CORDIS), is the European Commission Partners Service for collaboration requests
-
The Dutch Research Council (NWO) is the most important science funding bodies in the Netherlands and realises quality and innovation in science
Find collaborators around Groningen
The Science Shops, together with WIJS, foster local collaborations between the university and the public. Find out more here.
Find collaborators at the University
-
The UG research portal showcases the University’s research output and activities. Every UG and UMCG staff member, including PhD students, has a profile page on the UG research portal. Make sure to keep your own profile up-to-date so that others may find you too!
What are collaboration best practices?
Research collaborations can significantly enhance the quality, scope, and impact of scientific investigations. However, successful collaborations require careful planning, clear communication, and mutual respect. Follow RISe's twelve points for a successful research collaboration.
The Twelve Labours of Research Collaboration
-
Slay Ambuiguity - Establish Clear Objectives and Goals: Ensure a shared understanding of the research goals, objectives, and expected outcomes among all collaborators. Define how each collaborator’s expertise will contribute to achieving them.
-
Capture Responsibility - Define Roles and Responsibilities: Clearly define the roles and responsibilities of each team member to avoid duplication of effort and ensure comprehensive task coverage. Establish a leadership structure and decision-making processes. Designate a project leader or principal investigator.
-
Tame Uncertainty - Develop a Collaboration Agreement: Create a formal agreement that outlines the terms of the collaboration, including intellectual property rights, publication policies, data sharing, and conflict resolution. Specify how funding and resources will be shared and managed. Enlist the help of the UG's General & Legal Affairs.
-
Purge Miscommunication - Communicate Effectively: Schedule regular meetings and use collaborative tools such as project management software, shared drives, and communication platforms to facilitate smooth and effective communication among team members.
-
Retrieve Information - Manage and Share Data Responsibly: Develop a data management plan addressing data collection, storage, sharing, and preservation, ensuring appropriate and secure access for all collaborators. For this, consider using the UG's Virtual Research Workspace.
-
Inspire Trust - Foster Mutual Respect and Trust: Value and respect the expertise and contributions of all collaborators, building secure knowledge and trust through transparency and reliability. Ensure consistent follow-through on commitments.
-
Protect Ownership - Clarify Intellectual Property and Authorship: Define intellectual property rights and authorship criteria early, following ethical guidelines and giving appropriate credit to all contributors.
-
Combat Conflict - Address Conflicts Constructively: Develop a conflict management plan and involve a neutral third party if necessary to mediate and resolve disputes.
-
Watch Progress - Monitor and Evaluate Progress Regularly: Regularly monitor the collaboration's progress against project goals and timelines, using defined metrics to evaluate success and output quality.
-
Harness Ethics - Uphold Ethical Standards: Conduct all research ethically, complying with relevant regulations and guidelines, and obtain informed consent from research participants when applicable.
-
Encourage Training - Provide Training and Capacity Building: Offer opportunities for skill development and knowledge sharing among team members to enhance overall collaboration.
-
Erect Perpetuity - Ensure Sustainability and Continuity: Plan for the long-term sustainability of the collaboration, identifying future project opportunities and maintaining comprehensive documentation for continuity.
Where can I find support for my innovative projects?
UG Technical Support
The Centre for Information Technology (CIT) provides Research and Innovation Support in the form of IT support for your innovations. Whether you want to safely store your large amounts of data, need a huge amount of computing power or extremely fast internet connections, would like help in writing the IT section in a grant application, to disseminate knowledge, or in choosing the right tools when designing your research, RIS can think along with you. These are just a few of the options.
UG Business support
The IP & Business Development team provides support regarding intellectual property, patent applications, licensing, public-private partnerships, and new start-ups.
For other support with innovation, you may be interested in the incubator of Campus Groningen .
Engaging Stakeholders
How can I share my research with a wider audience?
There are many ways for your research to reach a wider audience, from presenting at conferences, to sharing on social media, a personal website or blog, collaborating with media outlets or engaging with public science communication events. What medium you chose primarily depends on the type of audience you hope to reach.
I would like to commercialize my findings. Can you help me?
Research findings and innovations come in many forms, and one way for it to have a societal or academic impact is by creating a research-based product. This can be an app, a software, a patented design, a start-up, etc. Such product can potentially be commercialized.
At RISe we do not provide support for such endeavour, but you can find facilitators here:
-
IP & Business Development (support with matters of intellectual property, patents, start-up creation, etc.)
-
RUG Ventures (investment company)
-
Campus Groningen (incubator)
-
UMCG's Innovation Center (for health innovations)
-
Sustainable Startup Academy (course with practical tools)
How do I create an app based on my research?
That's a great way to disseminate your research! The University of Cambridge has put together a quick-guide on how to get started.
Should I translate my research?
By translating your research and communication into different languages, you can reach audiences that would otherwise not have access to it. For instance, if your research concerns a certain population in the Netherlands, you might want to translate it into Dutch.
You don't need to do it all yourself! The University Translation and Correction Service (UVC) helps clients both within and outside of the University of Groningen to translate their documents.
Measuring Academic & Societal Impact
What are the ethics of research intelligence?
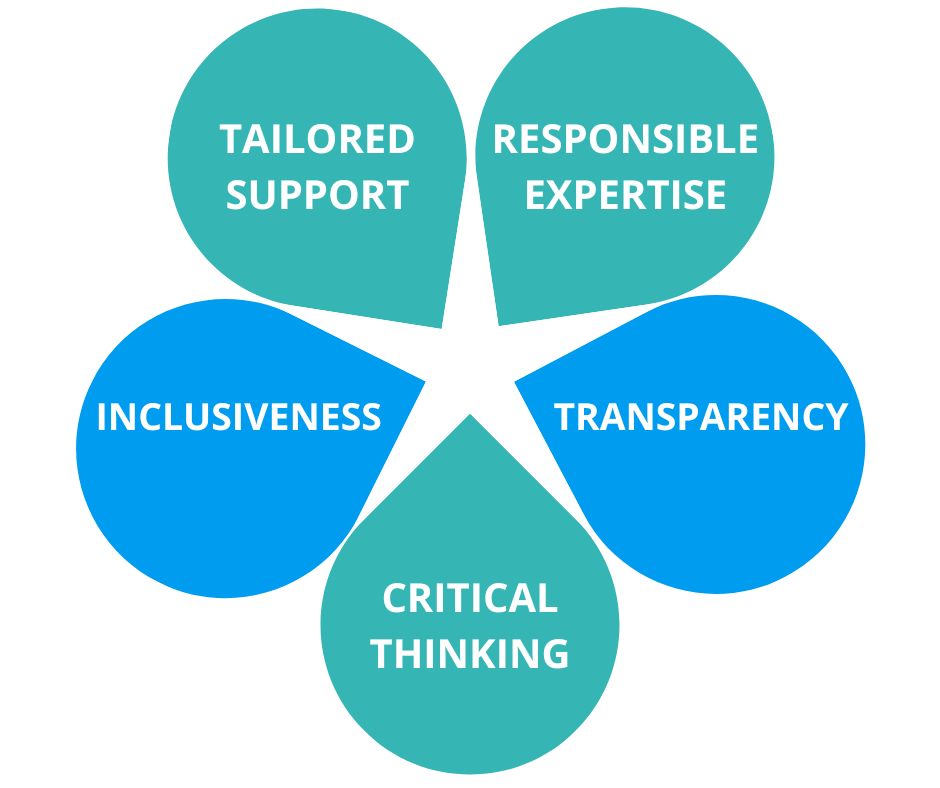
We strive to conduct our research intelligence analyses as ethically as possible, following our five core values:
-
Tailored support: we tailor our analyses to the mission of the research units.
-
Responsible expertise: we ensure the responsible and expert utilization of metrics across all practices at the UG.
-
Transparency: we openly share research assessment data and analyses.
-
Critical thinking: we thoughtfully select metrics that best serve their intended purposes and acknowledge their strengths and limitations.
-
Inclusiveness: we recognize the diverse nature of research disciplines and the varying research practices within them.
The University of Groningen recognizes the importance of using bibliometrics and altmetrics responsibly and adheres to the principles propagated in the Leiden Manifesto. The increasing sophistication of our benchmark tools allows us to do in-house analyses and provide benchmarks that can be used in various activities pertaining to the assessment of academic and societal impact, including SEP evaluations. As a result, the Policy and Strategy department of the Office of the University of Groningen has called for the prudent use of benchmarking tools and produced a set of guidelines for responsible research assessment.
How do I measure my academic impact? What are bibliometrics?
Bibliometrics
Bibliometrics is the quantitative analysis of academic output, impact, and collaboration. Information on these is provided through quantitative bibliometric indicators.
Bibliometric analysis is used to evaluate research performance by a wide range of contributors --- PhD candidates, researchers, institute directors, administrators, university policymakers --- to build research profiles and identify important patterns and trends within any domain of interest.
Due to limitations associated with bibliometrics, these measures should always be used in conjunction with qualitative evidence, such as peer review, to ensure the most complete and accurate input in answering a question.
Read more about the principles of using bibliometrics in responsible research assessment.
We can help you create research performance reports for the UG research community at different levels of analysis. Don’t hesitate to contact us at rise rug.nl with your requests.

SciVal
SciVal is an analytics tool offered by Elsevier. The platform enables us to visualize research performance data, benchmark against other institutions, analyze collaborative partnerships, and uncover research trends. Scival sources its data from Scopus, Elsevier’s database of abstracts and citations of peer-reviewed literature.
While Scopus maintains that it is the largest of such databases, its coverage of certain disciplines, especially the humanities, remains limited.
Use your university credentials to log into SciVal. Don’t hesitate to contact us at rise rug.nl for support with access and use!
Why can FWCI be misleading when analyzing publication sets?
The Field-Weighted Citation Impact is the ratio of the total citations actually received by an entity (researcher, research group, department, university, etc), and the total citations that would be expected based on the average of the subject field (see Scopus knowledgebase ). As such, it provides a "level playing field" for comparison as publications are compared to the average in their particular field, type and publication year.
However, when analyzing a larger publication set, simply calculating the average FWCI for this set can be very misleading especially when making a comparison between two such sets produced by two similar research groups. In cases like this, we recommend that you instead look at and plot the frequency distribution of the FWCIs of the publication set. For a clear example and more details, see "Profiles, not Metrics " paper published by the Web of Science Institute for Scientific Information (Jan, 2019).
What are Scival’s field-weighted citation percentiles pitfalls?
When conducting bibliometric analysis, we often stress the importance of field-weighted indicators as these ensure fair comparison across document type, publication year and research area.
However, a blog post posted on the Bibliomagician platform recently exposed a subtle difference in Scival when computing field-weighted citation percentiles compared to the traditional bibliometric approach.
In a nutshell, instead of using total citation counts for each publication in the dataset under analysis, Scival uses citation ratios. Moreover, Scival merges subject areas before computing the top percentiles. As noted by the blog post authors, Scival’s method doesn’t lead to very different results for large datasets. However, it certainly affects the analysis for small datasets especially when that set includes publications from more subject areas, which have very different citation distributions.
We strongly encourage anyone using Scival to carefully read the whole blog post and send us any additional questions that may arise.